11分钟宕机教训:Webman 内存泄露排查与性能优化实战
一、案例背景:长假后的 11 分钟生产事故
某日早晨,公司基于 Webman 开发的核心 API 服务突发宕机,服务器响应中断,最终导致业务停摆 11 分钟。
异常表现:
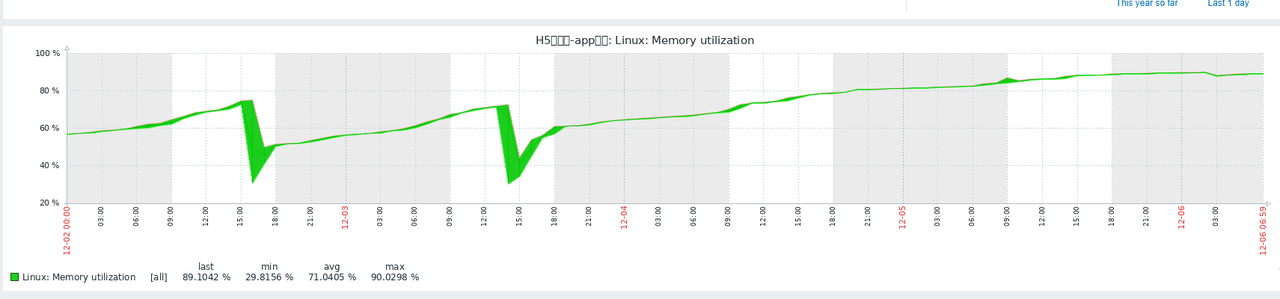
内存持续攀升: 该服务启动初期内存占用约为 40%,运行 2 天后会增长至 80%。
运维压力: 由于内存无法自动释放,此前必须每 2 天手动重启服务。
触发原因: 本次事故正值节假日后,由于长假期间缺乏人工干预,内存最终耗尽导致系统崩溃。
反思: 依靠手动重启维持的服务架构,在长假面前极度脆弱。
二、 深度排查:定位内存增长的“元凶”
参考 Webman 官方文档关于内存泄露的说明,我们按优先级进行了逐一排查:
1. 代码层面检测
首先排查了 PHP 常驻内存中最常见的泄露点:
无限膨胀的static数组
无限膨胀的单例数组属性
无限膨胀的global数组
结果: 经过代码审计,并未发现上述明显的编程错误。
2. 运行机制分析
排除代码 bug 后,我们将目光转向 PHP 的内存分配机制。在处理大文件上传、大批量数据库查询或解析超大 Excel 时,PHP 会申请大量内存。
机制痛点: 请求结束后 Webman 虽然释放了逻辑层面的内存,但 PHP 解释器为了后续复用性能,并不会立即将内存还给 OS。
监控失效: Webman 自带的 monitor 进程监控由于 memory_limit 配置过大(512M),导致在触发进程重启阈值前,服务器物理内存已先被耗尽。
3. 架构耦合问题
进一步排查发现,该服务将 API 接口、定时任务(Crontab) 与 队列消费者(Redis-queue) 混合在同一进程池中启动。复杂的常驻脚本进一步加剧了内存管理的难度。
三、 优化策略:服务拆分与精准配额
为了彻底解决此问题,我们实施了**“动静分离”与“精细化配置”**的优化方案:
1. 引入“慢服务”隔离机制
针对不同复杂度的接口进行资源隔离:
高耗能接口(慢服务): 将大内存占用、长响应时间的接口剥离到独立服务,配置较低的进程数和适中的 memory_limit (256M),防止单接口拖垮全局。
常规接口(轻服务): 保持高并发进程数,设置较小的 memory_limit (64M)。一旦某个进程处理异常请求导致内存上涨,能迅速触发 monitor 的重启机制。
2. 业务脚本彻底剥离
将定时任务和队列消费脚本从 Web 服务中剥离,改由 CLI 独立启动:
- 稳定性: API 发版重启不再导致后台任务中断。
- 解耦: 脚本与 Web 服务互不干扰,可根据业务负载独立扩展。
四、 优化效果
经过一周的观察,优化效果显著:
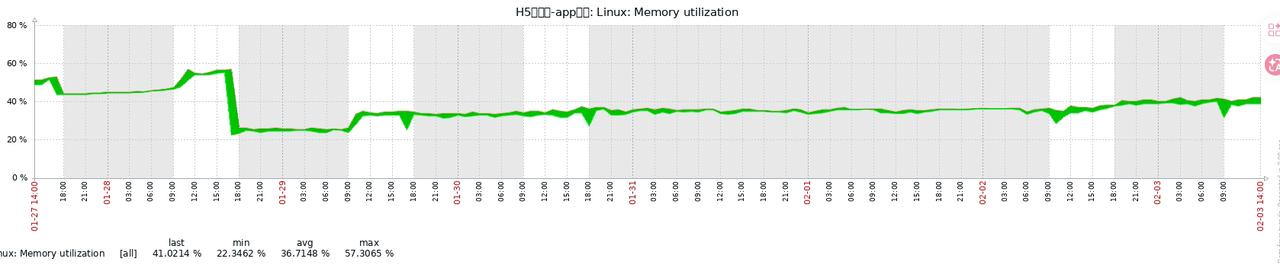
内存基准: 启动初始内存占用从 40% 降至 35%。
长期稳定性: 连续运行 5 天后,内存始终稳定在 40% 左右的健康水平,无需再进行人工干预。